Three weeks ago I benchmarked the best open-source speech-to-text models on Dutch parliamentary audio. The result was disappointing. None of them were actually good at Dutch. So I trained one. The result: Murmel v1, which achieves 17.3% word error rate, beating every open-source alternative. At The AI Factory, we specialise in building AI applications for Dutch organisations. In the process, through platforms like Parlinq.com, I've collected enormous quantities of Dutch speech data: thousands of hours of transcribed parliamentary debates, public data sources and more. In addition to that work, I've been working on collecting and processing Dutch speech data and training my own model. Now it's time to share the first results. Speech-to-text is the first type of model we will release. I call it Murmel: because the goal is to build a model that will even understand people who murmelen (Dutch for mumbling).
From benchmarking to training
The benchmark I recently did made one thing clear: there is space for a Dutch-optimised speech model. The general-purpose open-source models, trained mostly on English, treated Dutch as an afterthought. They were decent, but "decent" isn't good enough when you're transcribing parliamentary debates, medical consultations, or legal proceedings where every word matters. It is time the Netherlands produces more technology instead of mostly consuming it.
Over the span of the last year I worked on collecting data that would allow for creating a better model. The training set spans thousands and thousands of hours of Dutch speech: parliamentary debates, Dutch broadcasts from public broadcasting, and a multitude of public sources. It contains Dutch that is actually spoken: formal and informal, fast and slow, Randstad and regional, native and non-native.
The results
When evaluating Murmel on the same data as the recent benchmark, it achieves a 17.3% word error rate. The benchmark contains 1,662 segments across 9 hours of real parliamentary audio. On this dataset, Murmel makes roughly one in six fewer errors than the next best model.
For context, that model is Voxtral-small for Mistral, which topped my open-source benchmark three weeks ago at 20.8%. For the non-technical reader: word error rate measures what percentage of words the model gets wrong. Lower is better. The chart below tells the story at a glance: that difference is clearly noticeable when reading transcripts.
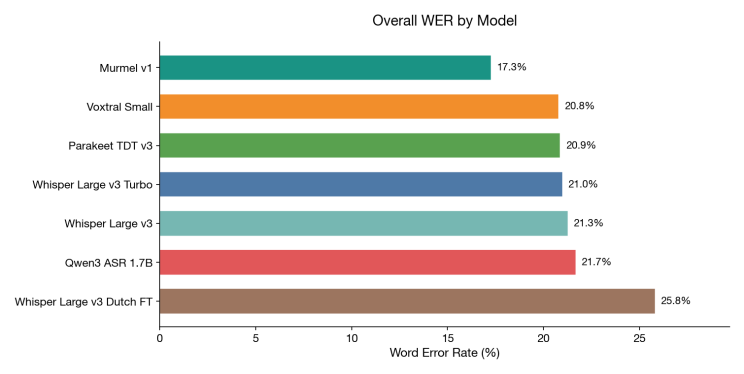
Word Error Rate, lower is better
It wins everywhere, not just overall
What makes these results convincing is that Murmel doesn't just win on the aggregate number. It leads in virtually every subcategory I tested.
The single most striking result: on question time (Vragenuur), Murmel achieves 5.8% WER, nearly half the error rate of the competition. On committee meetings (Notaoverleg) it scores 7.8% versus 10.9% for the next best model. Even on plenary debates, where all models struggle, Murmel leads at 20.6% versus 22.0%.
By gender: Murmel scores 11.9% WER on female speakers and 18.4% on male speakers. Every other model sits above 16% on female speakers and above 21% on male speakers. The gender gap is still there (an important finding that needs more research), but Murmel is more accurate for both.
By regional accent: speakers from Limburg, historically among the hardest to transcribe accurately, score 14.6% WER with Murmel versus 17.9%–23.9% for other models. Speakers from Groningen score 6.4% versus 9.3%–12.9%. The pattern holds across every province tested.
By speaker background: for speakers born outside the Netherlands, Murmel scores 12.4% WER. The other models range from 16.1% to 20.7%. The improvement is consistent regardless of the speaker's origin.
These results are encouraging, but I aim to enhance them even further as I continue training with more data and compute. One important caveat: parliamentary speech is more prepared than a medical consultation or field interview. Generalisation to fully spontaneous speech is an active area of development, and honest evaluation on those domains is something we will pick up with the right partner.
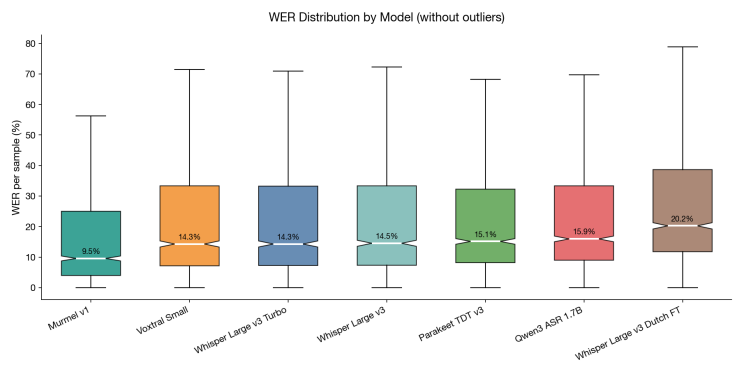
Word Error Rate distribution by Model, lower is better
How I built it
Murmel's architecture is based on state-of-the-art speech recognition research. It allows the model to deeply learn Dutch phonetics, and vocabulary throughout its entire network, rather than making surface-level adjustments. Combined with a large, diverse training set covering a wide variety of names, topics and speakers from every province and background, the result is a model that generalises well across Dutch speech contexts.
Compute is the bottleneck, but the model is ready to use
Let's be straightforward: compute is currently my biggest constraint. Without venture capital money, the GPU time required to train a full speech model is a bottleneck. My training runs haven't been as long as I'd like, and the learning curves suggest the model hasn't fully converged, meaning I'm leaving performance on the table. In addition to that, I even managed to collect more and more data since training this model.
But Murmel v1 is already robust and ready to be used for production application. A 17.3% WER that leads every open-source alternative is a strong foundation, and for many use cases, especially when combined with domain-specific post-processing, it's production-ready today. The current focus is on recorded audio; but we would love to spin up the hardware for real-time and streaming transcription when the use case requires that.
So the plan is to start building applications with Murmel now, and to keep making the model better and better whilst doing that. The model can still be improved in a multitude of ways, but first it is time to validate there is a demand. And of course, as always, the best products are developed to solve problems.
We're looking for testing partners
This is where you come in. We're actively looking for organisations that want to test Murmel on their own Dutch audio. Whether that's gemeenteraadsvergaderingen, medical consultations, legal proceedings (including domain-specific vocabulary adaptation), call centre recordings, or anything else, we want to understand how the model performs across real-world use cases.
If you have a problem involving Dutch audio and an impactful use case, please reach out! We can run Murmel on your data on EU-based infrastructure, designed for high-volume transcription pipelines, compare it against whatever you're currently using, and give you an honest assessment of where it helps and where it still falls short. For public sector organisations navigating the EU AI Act, EU-hosted and auditable infrastructure is increasingly a requirement rather than a preference, Murmel is built with that in mind.
Built in Europe, for Europe, with Europe
Murmel is not perfect yet, and there's meaningful work left to do. But the direction is clear: a purpose-built Dutch model outperforms every general-purpose alternative, and the gap will only grow. Dutch is where we start. But the same problem exists for German, French, Polish, and every other European language that gets second-class treatment from models trained primarily on English.
The infrastructure we're building, EU-hosted, purpose-trained, GDPR-compliant, is designed to scale across languages. The Netherlands has world-class AI talent. It's time we had world-class Dutch AI.
Try Murmel
If you're working with Dutch audio, council meetings, medical consultations, call centre recordings, legal proceedings, or anything in between, join the waitlist at the-ai-factory.com/murmel to get early access to the interface and API, or reach out if your organisation would like to test Murmel on real-world data.
Want to explore what Murmel can do for your Dutch audio workflows?
Get expert advice