Drie weken geleden benchmarkte ik de beste open-source spraak-naar-tekst modellen op Nederlandse parlementaire audio. Het resultaat was teleurstellend. Geen van hen was echt goed in Nederlands. Dus heb ik er een getraind. Het resultaat: Murmel v1, dat 17,3% woordfoutenpercentage behaalt en daarmee elk open-source alternatief verslaat. Bij The AI Factory zijn we gespecialiseerd in het bouwen van AI-applicaties voor Nederlandse organisaties. Daarbij heb ik, via platforms als Parlinq.com, enorme hoeveelheden Nederlandse spraakdata verzameld: duizenden uren getranscribeerde parlementaire debatten, publieke databronnen en meer. Daarnaast heb ik gewerkt aan het verzamelen en verwerken van Nederlandse spraakdata en het trainen van mijn eigen model. Nu is het tijd om de eerste resultaten te delen. Spraak-naar-tekst is het eerste type model dat we uitbrengen. Ik noem het Murmel: omdat het doel is een model te bouwen dat zelfs mensen verstaat die murmelen.
Van benchmarking naar training
De benchmark die ik onlangs deed maakte één ding duidelijk: er is ruimte voor een Nederlands-geoptimaliseerd spraakmodel. De algemene open-source modellen, voornamelijk getraind op Engels, behandelden Nederlands als een bijzaak. Ze waren redelijk, maar "redelijk" is niet goed genoeg als je parlementaire debatten, medische consulten of juridische procedures transcribeert waar elk woord ertoe doet. Het is tijd dat Nederland meer technologie produceert in plaats van voornamelijk te consumeren.
Het afgelopen jaar heb ik gewerkt aan het verzamelen van data die het mogelijk maakt om een beter model te bouwen. De trainingsset omvat duizenden en duizenden uren Nederlandse spraak: parlementaire debatten, Nederlandse uitzendingen van de publieke omroep, en een veelheid aan publieke bronnen. Het bevat Nederlands dat daadwerkelijk gesproken wordt: formeel en informeel, snel en langzaam, Randstad en regionaal, moedertaal en niet-moedertaal.
De resultaten
Bij de evaluatie van Murmel op dezelfde data als de recente benchmark behaalt het een woordfoutenpercentage van 17,3%. De benchmark bevat 1.662 segmenten over 9 uur echte parlementaire audio. Op deze dataset maakt Murmel ruwweg één op de zes minder fouten dan het op één na beste model.
Ter context: dat model is Voxtral-small van Mistral, dat drie weken geleden mijn open-source benchmark aanvoerde met 20,8%. Voor de niet-technische lezer: woordfoutenpercentage meet welk percentage woorden het model fout heeft. Lager is beter. De onderstaande grafiek vertelt het verhaal in één oogopslag: dat verschil is duidelijk merkbaar bij het lezen van transcripties.
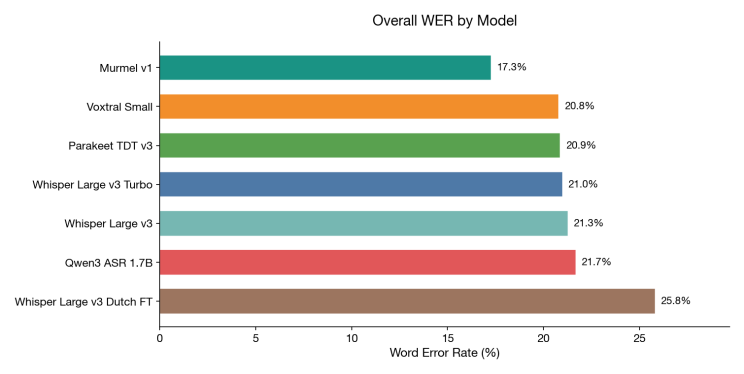
Woordfoutenpercentage, lager is beter
Het wint overal, niet alleen overall
Wat deze resultaten overtuigend maakt, is dat Murmel niet alleen wint op het totaalcijfer. Het leidt in vrijwel elke subcategorie die ik heb getest.
Het meest opvallende resultaat: bij het Vragenuur behaalt Murmel 5,8% WER, bijna de helft van het foutenpercentage van de concurrentie. Bij Notaoverleg scoort het 7,8% versus 10,9% voor het op één na beste model. Zelfs bij plenaire debatten, waar alle modellen moeite hebben, leidt Murmel met 20,6% versus 22,0%.
Op geslacht: Murmel scoort 11,9% WER voor vrouwelijke sprekers en 18,4% op mannelijke sprekers. Elk ander model zit boven de 16% voor vrouwelijke sprekers en boven de 21% voor mannelijke sprekers. Het geslachtsverschil is er nog (een belangrijke bevinding die meer onderzoek verdient), maar Murmel is nauwkeuriger voor beide.
Op regionaal accent: sprekers uit Limburg, historisch gezien het moeilijkst om nauwkeurig te transcriberen, scoren 14,6% WER met Murmel versus 17,9%–23,9% voor andere modellen. Sprekers uit Groningen scoren 6,4% versus 9,3%–12,9%. Het patroon geldt voor elke geteste provincie.
Op achtergrond: voor sprekers geboren buiten Nederland scoort Murmel 12,4% WER. De andere modellen variëren van 16,1% tot 20,7%. De verbetering is consistent ongeacht de herkomst van de spreker.
Deze resultaten zijn bemoedigend, maar ik streef ernaar ze verder te verbeteren naarmate ik blijf trainen met meer data en compute. Een belangrijke kanttekening: parlementaire spraak is meer voorbereid dan een medisch consult of veldinterview. Generalisatie naar volledig spontane spraak is een actief ontwikkelingsgebied, en eerlijke evaluatie op die domeinen is iets dat we oppakken met de juiste partner.
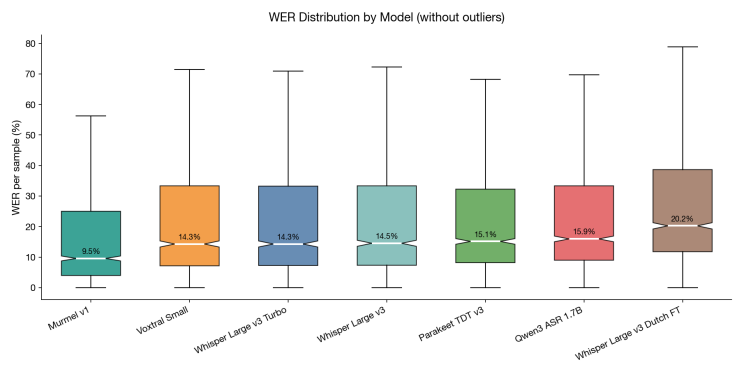
Woordfoutenpercentage verdeling per Model, lager is beter
Hoe ik het gebouwd heb
De architectuur van Murmel is gebaseerd op state-of-the-art spraakherkenningsonderzoek. Het stelt het model in staat om diepgaand Nederlandse fonetiek en vocabulaire te leren door het gehele netwerk, in plaats van oppervlakkige aanpassingen te maken. Gecombineerd met een grote, diverse trainingsset die een breed scala aan namen, onderwerpen en sprekers dekt uit elke provincie en achtergrond, is het resultaat een model dat goed generaliseert over Nederlandse spraakcontexten.
Compute is het knelpunt, maar het model is klaar voor gebruik
Laten we direct zijn: compute is momenteel mijn grootste beperking. Zonder durfkapitaal is de GPU-tijd die nodig is om een volledig spraakmodel te trainen een knelpunt. Mijn trainingsruns zijn niet zo lang geweest als ik zou willen, en de leercurves suggereren dat het model nog niet volledig is geconvergeerd, wat betekent dat ik prestatie op tafel laat liggen. Bovendien heb ik het zelfs voor elkaar gekregen om steeds meer data te verzamelen sinds het trainen van dit model.
Maar Murmel v1 is al robuust en klaar om te worden gebruikt voor productietoepassingen. Een WER van 17,3% dat elk open-source alternatief aanvoert is een sterke basis, en voor veel use cases, vooral in combinatie met domeinspecifieke nabewerking, is het vandaag al productieklaar. De huidige focus ligt op opgenomen audio; maar we zetten graag de hardware op voor real-time en streaming transcriptie wanneer de use case dat vereist.
Het plan is dus om nu applicaties te gaan bouwen met Murmel, en het model daarbij steeds beter te blijven maken. Het model kan nog op vele manieren worden verbeterd, maar eerst is het tijd om te valideren dat er vraag is. En natuurlijk, zoals altijd, worden de beste producten ontwikkeld om problemen op te lossen.
We zoeken testpartners
Hier komt u in beeld. We zijn actief op zoek naar organisaties die Murmel willen testen op hun eigen Nederlandse audio. Of het nu gaat om gemeenteraadsvergaderingen, medische consulten, juridische procedures (inclusief domeinspecifieke vocabulaire-aanpassing), callcenteropnames, of iets anders, we willen begrijpen hoe het model presteert bij real-world use cases.
Als u een probleem heeft met Nederlandse audio en een impactvolle use case, neem dan contact op! We kunnen Murmel draaien op uw data op EU-gebaseerde infrastructuur, ontworpen voor high-volume transcriptiepipelines, het vergelijken met wat u momenteel gebruikt, en u een eerlijke beoordeling geven van waar het helpt en waar het nog tekortschiet. Voor publieke organisaties die navigeren door de EU AI Act is EU-gehoste en controleerbare infrastructuur steeds meer een vereiste dan een voorkeur, Murmel is daar rekening mee gebouwd.
Gebouwd in Europa, voor Europa, met Europa
Murmel is nog niet perfect, en er is nog betekenisvol werk te doen. Maar de richting is duidelijk: een speciaalgebouwd Nederlands model presteert beter dan elk algemeen alternatief, en de kloof zal alleen maar groeien. Nederlands is waar we beginnen. Maar hetzelfde probleem bestaat voor Duits, Frans, Pools, en elke andere Europese taal die tweederangsbehandeling krijgt van modellen die voornamelijk op Engels zijn getraind.
De infrastructuur die we bouwen, EU-gehost, doelgericht getraind, AVG-compliant, is ontworpen om over talen te schalen. Nederland heeft AI-talent van wereldklasse. Het is tijd dat we ook Nederlands AI van wereldklasse krijgen.
Probeer Murmel
Werkt u met Nederlandse audio, raadsvergaderingen, medische consulten, callcenteropnames, juridische procedures, of iets daartussenin, schrijf u in op de wachtlijst op the-ai-factory.com/murmel voor vroege toegang tot de interface en API, of neem contact op als uw organisatie Murmel wil testen op echte data.
Wil je ontdekken wat Murmel kan betekenen voor jouw Nederlandse audioworkflows?
Vraag advies aan